Bayesian Interrupted Time Series#
Interrupted Time Series (ITS) analysis is a powerful approach for estimating the causal impact of an intervention or treatment when you have a single time series of observations. The key idea is to compare what actually happened after the intervention to what would have happened in the absence of the intervention (the “counterfactual”). To do this, we train a statistical model on the pre-intervention data (when no treatment has occurred) and then use this model to forecast the expected outcomes into the post-intervention period as-if treatment had not occurred. The difference between the observed outcomes and these model-based counterfactual predictions provides an estimate of the causal effect of the intervention, along with a measure of uncertainty if using a Bayesian approach.
What do we mean by causal impact in Interrupted Time Series?#
In the context of interrupted time series analysis, the term causal impact refers to the estimated effect of an intervention or event on an outcome of interest. We can break this down into two components which tell us different aspects of the intervention’s effect:
The Instantaneous Bayesian Causal Effect at each time point is the difference between the observed outcome and the model’s posterior predictive distribution for the counterfactual (i.e., what would have happened without the intervention). This is not just a single number, but a full probability distribution that reflects our uncertainty.
The Cumulative Bayesian Causal Impact is the sum of these instantaneous effects over the post-intervention period, again represented as a distribution.
Let \(y_t\) be the observed outcome at time \(t\) (after the intervention), and \(\tilde{y}_t\) be the model’s counterfactual prediction for the same time point. Then:
Instantaneous effect: \(\Delta_t = y_t - \tilde{y}_t\)
Cumulative effect (up to time \(T\)): \(C_T = \sum_{t=1}^T \Delta_t\)
In Bayesian analysis, both \(\tilde{y}_t\) and \(\Delta_t\) are distributions, not just point estimates.
Why does this matter for decision making?#
These metrics allow you to answer questions like:
“How much did the intervention change the outcome, compared to what would have happened otherwise?”
“What is the total effect of the intervention over time, and how certain are we about it?”
By providing both instantaneous and cumulative effects, along with their uncertainty, you can make more informed business decisions and better understand the impact of your interventions.
Interrupted Time Series example#
import arviz as az
import pandas as pd
import causalpy as cp
%load_ext autoreload
%autoreload 2
%config InlineBackend.figure_format = 'retina'
seed = 42
Load data
df = (
cp.load_data("its")
.assign(date=lambda x: pd.to_datetime(x["date"]))
.set_index("date")
)
treatment_time = pd.to_datetime("2017-01-01")
df.head()
| month | year | t | y | |
|---|---|---|---|---|
| date | ||||
| 2010-01-31 | 1 | 2010 | 0 | 25.058186 |
| 2010-02-28 | 2 | 2010 | 1 | 27.189812 |
| 2010-03-31 | 3 | 2010 | 2 | 26.487551 |
| 2010-04-30 | 4 | 2010 | 3 | 31.241716 |
| 2010-05-31 | 5 | 2010 | 4 | 40.753973 |
Run the analysis
Note
The random_seed keyword argument for the PyMC sampler is not necessary. We use it here so that the results are reproducible.
result = cp.InterruptedTimeSeries(
df,
treatment_time,
formula="y ~ 1 + t + C(month)",
model=cp.pymc_models.LinearRegression(sample_kwargs={"random_seed": seed}),
)
Show code cell output
Auto-assigning NUTS sampler...
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [beta, sigma]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 2 seconds.
Sampling: [beta, sigma, y_hat]
Sampling: [y_hat]
Sampling: [y_hat]
Sampling: [y_hat]
Sampling: [y_hat]
fig, ax = result.plot()
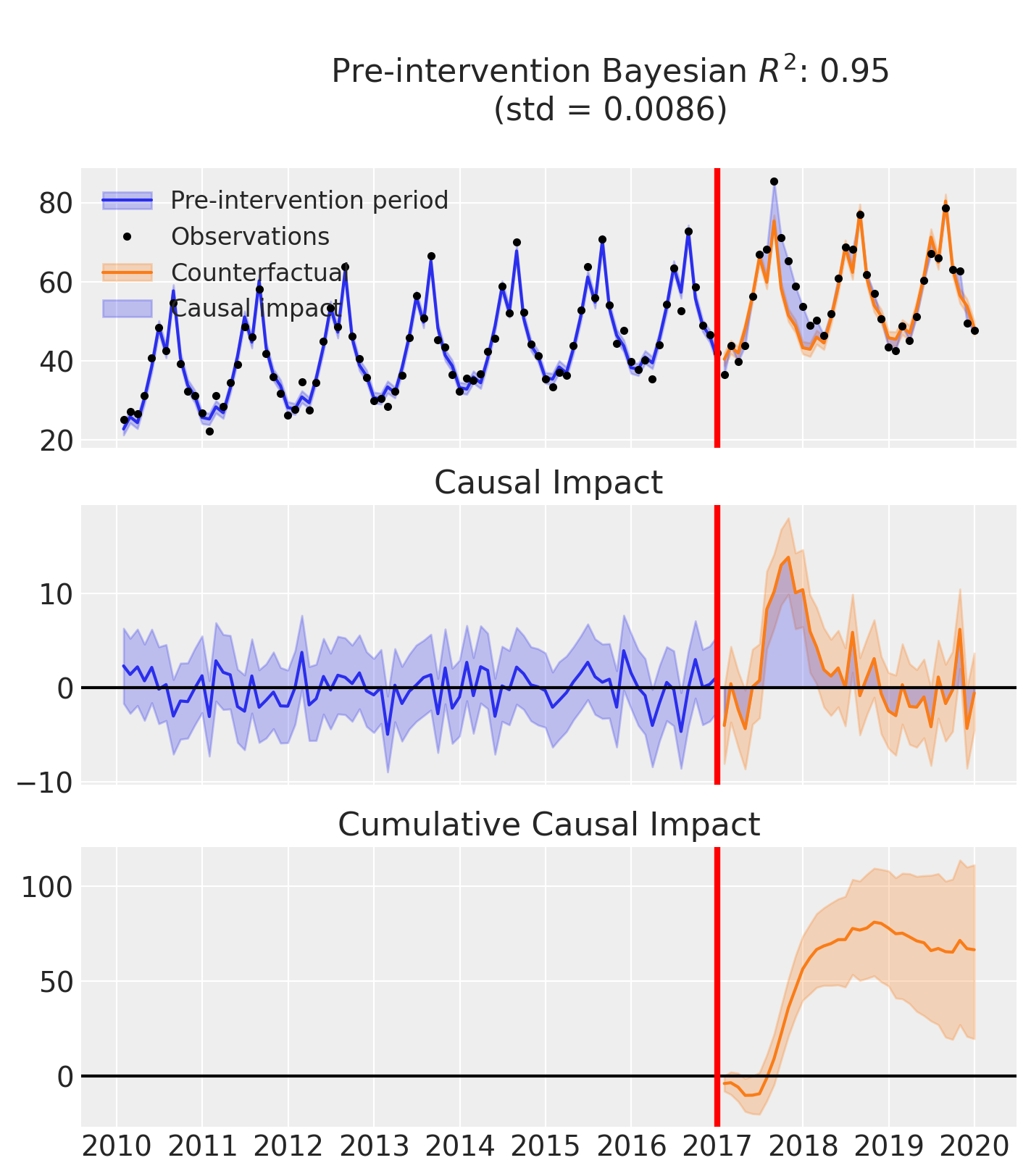
result.summary()
==================================Pre-Post Fit==================================
Formula: y ~ 1 + t + C(month)
Model coefficients:
Intercept 23, 94% HDI [21, 24]
C(month)[T.2] 2.9, 94% HDI [0.88, 4.8]
C(month)[T.3] 1.2, 94% HDI [-0.81, 3.1]
C(month)[T.4] 7.1, 94% HDI [5.2, 9.1]
C(month)[T.5] 15, 94% HDI [13, 17]
C(month)[T.6] 25, 94% HDI [23, 27]
C(month)[T.7] 18, 94% HDI [16, 20]
C(month)[T.8] 33, 94% HDI [32, 35]
C(month)[T.9] 16, 94% HDI [14, 18]
C(month)[T.10] 9.2, 94% HDI [7.2, 11]
C(month)[T.11] 6.3, 94% HDI [4.2, 8.2]
C(month)[T.12] 0.59, 94% HDI [-1.4, 2.5]
t 0.21, 94% HDI [0.19, 0.23]
sigma 2, 94% HDI [1.7, 2.3]
As well as the model coefficients, we might be interested in the average causal impact and average cumulative causal impact.
First we ask for summary statistics of the causal impact over the entire post-intervention period.
az.summary(result.post_impact.mean("obs_ind"))
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| x | 1.845 | 0.677 | 0.542 | 3.086 | 0.013 | 0.009 | 2631.0 | 3110.0 | 1.0 |
Warning
Care must be taken with the mean impact statistic. It only makes sense to use this statistic if it looks like the intervention had a lasting (and roughly constant) effect on the outcome variable. If the effect is transient, then clearly there will be a lot of post-intervention period where the impact of the intervention has ‘worn off’. If so, then it will be hard to interpret the mean impacts real meaning.
We can also ask for the summary statistics of the cumulative causal impact.
# get index of the final time point
index = result.post_impact_cumulative.obs_ind.max()
# grab the posterior distribution of the cumulative impact at this final time point
last_cumulative_estimate = result.post_impact_cumulative.sel({"obs_ind": index})
# get summary stats
az.summary(last_cumulative_estimate)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| x | 66.436 | 24.359 | 19.508 | 111.108 | 0.476 | 0.337 | 2631.0 | 3110.0 | 1.0 |